-Bsymbolic When creating a shared library, bind references to global symbols to the definition within the shared library, if any. Normally, it is possible for a program linked against a shared library to override the definition within the shared library. This option can also be used with the –export-dynamic option, when creating a position independent executable, to bind references to global symbols to the definition within the executable. This option is only meaningful on ELF platforms which support shared libraries and position independent executables.
Set the default ELF image symbol visibility to the specified option—all symbols are marked with this unless overridden within the code. Using this feature can very substantially improve linking and load times of shared object libraries, produce more optimized code, provide near-perfect API export and prevent symbol clashes(防止标志符冲突). It is strongly recommended that you use this in any shared objects you distribute(强烈建议使用在你写的共享库). … …
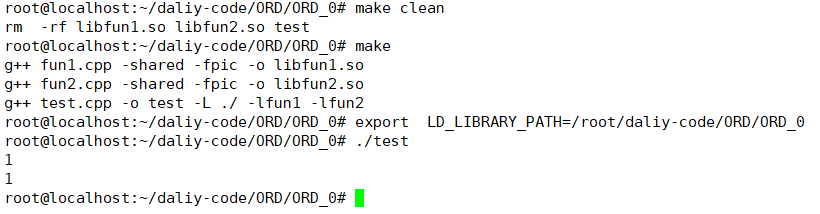
修改头文件
fun1.h
#include <stdio.h>
__attribute__ ((visibility("default"))) int print1();
fun2.h
#include <stdio.h>
__attribute__ ((visibility("default"))) int print2();
if(BUILD_SHARED_LIBS)
# Only export LEVELDB_EXPORT symbols from the shared library.
add_compile_options(-fvisibility=hidden)
endif(BUILD_SHARED_LIBS)
头文件export.h
// Copyright (c) 2017 The LevelDB Authors. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file. See the AUTHORS file for names of contributors.
#ifndef STORAGE_LEVELDB_INCLUDE_EXPORT_H_
#define STORAGE_LEVELDB_INCLUDE_EXPORT_H_
#if !defined(LEVELDB_EXPORT)
#if defined(LEVELDB_SHARED_LIBRARY)
#if defined(_WIN32)
//Windows 系列
#if defined(LEVELDB_COMPILE_LIBRARY)
#define LEVELDB_EXPORT __declspec(dllexport)
#else
#define LEVELDB_EXPORT __declspec(dllimport)
#endif // defined(LEVELDB_COMPILE_LIBRARY)
#else // defined(_WIN32)
//Linux gcc系列
#if defined(LEVELDB_COMPILE_LIBRARY)
#define LEVELDB_EXPORT __attribute__((visibility("default")))
#else
#define LEVELDB_EXPORT
#endif
#endif // defined(_WIN32)
#else // defined(LEVELDB_SHARED_LIBRARY)
#define LEVELDB_EXPORT
#endif
#endif // !defined(LEVELDB_EXPORT)
#endif // STORAGE_LEVELDB_INCLUDE_EXPORT_H_
头文件db.h片段
...
namespace leveldb {
...
class LEVELDB_EXPORT DB {
...
};
...
}